
I teach a course called “Human and Machine Intelligence Alignment.” The basic idea is that there are productive analogies to be made in looking at the alignment problems generated by trying to live with machine intelligence, expert intelligence, organizational intelligence, and other human intelligences. The social and human sciences have been studying humans’ efforts at managing the last three for a long time.
The premise of the organizational intelligence component is that organizations are artificial, constructed super-human intelligences. We create organizations in the hope of amplifying the benefits of individual intelligence which attenuating its shortcomings. From a small hunting party on the African savannah to a multinational corporation the idea is to accomplish together what we cannot accomplish alone.
Humans recognize both the immense utility of organization and the risks associated with deploying organizations in the world. Institutions of social control and regulation emerged alongside the evolution of organization to ensure that it remained humanly beneficial.
Sometimes when we explore the analogy of organizations and AI we focus on how mechanical AI reveals all the imperfections of organizations, all the ways that real organizations are irrational and inefficient.
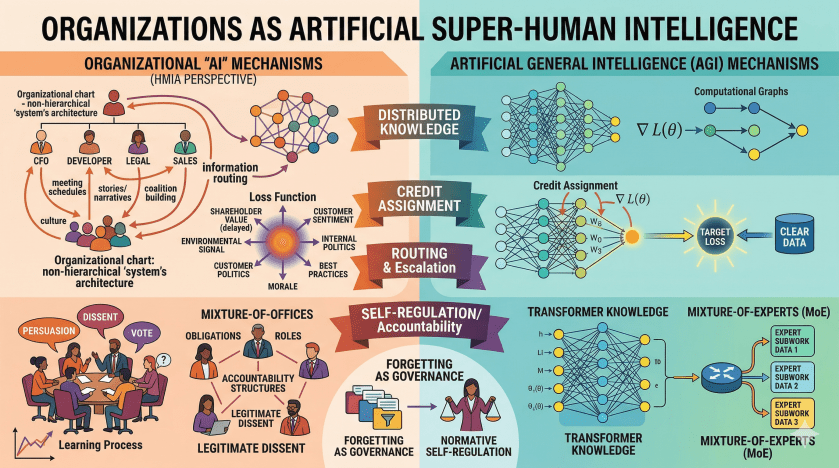
Superficially, parts of the analogy work remarkably well. The organizational “AI” isn’t in any one place, it’s distributed across people, practices, and structures, just like a transformer’s “knowledge” isn’t in any one layer. The organization “computes” by routing information: who talks to whom, what gets escalated, what gets ignored at the periphery.
But then we drill down a bit. The loss function is a challenge: organizations often can’t agree on what signal they’re optimizing. The loss function would be whatever environmental signal the organization is taking as a reflection of its success or failure. In theory, if it is a corporation, it is shareholder value but it’s rarely simple and clear in practice. The signal is delayed and proxified over and over. No consistent gradient here. And there is a constant barrage of internal and externally generated loss signals (morale, politics, instrumental goals, alternative reflexive views of the organization, best practice ideas from consultants). Organizations train on corrupted labels and distorted rewards.
The organization’s model architecture includes the structure of the organization its schedule of meetings, and the organization of the workplace. The topology of who-reports-to-whom and what-gets-discussed-where is the computational graph.
Optimization and learning rates are erratic because organizational learning requires social processes (persuasion, narrative, politics) not just information transfer. A new fact doesn’t update the organization; it takes a coalition that believes the new fact and has leverage. There might be an analog of gradient descent but the gradients have to win a committee vote. Credit assignment is an organizational task.
That litany could end as an attempted take-down of the organization vis a vis the more rational AI model. The benefit of the analogy might be just “sure, there are ways that you can see an organization through the lens of an ML model.” But what if we came at it from the other direction?
What have organizations figured out that ML hasn’t?
Maybe Coalition-based updating is a form of robustness. The fact that a new idea has to win in a committee before it changes practice is maddening, but it might be a filter against noise, manipulation, and fads. Is organizational “slow learning rate” partially a feature, a form of regularization that demands that a signal be strong and socially legible before it propagates?
A key characteristic of organizations is role differentiation. An obvious analog is mixture-of-experts, but we might get something extra in human organizations. Organizational roles aren’t just specialization; one occupies an “office”. An office comes with accountability structures, legitimate dissent channels, and escalation protocols. The agent is contracted to fulfill the obligations of the office and can recognize themselves as bound by that contract. The office system presupposes an occupant capable of normative self-regulation; the architecture is designed for that kind of agent. A CFO doesn’t just know finance; she knows what to do when the financial signal contradicts the strategic narrative, how to decide whether to make a fuss, and whom to tell; she knows how to be a good CFO. MoE systems route to experts, but probably lack a theory of what happens when experts disagree or when the question exceeds local competence or raises issues at another level of abstraction or when getting the answer right is less important than being accountable for how it was reached.
Organizations transmit knowledge more through stories than data. At first glance, this is inefficient by information-theoretic standards. Narrative is lossy compression but might it preserve and center what matters? Narrative affords reflection – the organization and its components paying attention to itself qua organization. Stories encode causality, agency, and what-to-do-next in ways that raw signals don’t.
A putative advantage of AI is that it remembers everything and has a constant synoptic perspective. Organizations pale in comparison. But forgetting might be a form of governance. Explicit retention policies, deciding what not to remember, shared systems of relevance that dynamically set aside portions of what is known, and cognitive limits are all forms of regularization layer on ethical and political alignment. Organizations make explicit choices about what the institution should carry forward. AI systems mostly just accumulate.
A large contributor to organizational intelligence safety – why it is safe to deploy organizations in society – is the capacity for accountability possessed by the units out of which OI is built.
The deepest difference may be about the nature of the unit rather than the architecture. Organizational intelligence is built from components that have a first-person relationship to their own actions — they can recognize themselves as the agent, hold themselves to account, and deviate from instruction on normative grounds. “Taking responsibility” is a reflexive act, not just a causal attribution imposed from outside.
This is different from credit assignment in ML. Backpropagation assigns credit, but the weight doesn’t know it was nudged, can’t feel the difference between a good and bad call, can’t refuse. In organizations, the grain at which accountability attaches is defined structurally through roles, but it works because the unit occupying the role has a self-concept that accountability hooks into. The subunit has the capacity for self-discipline.
Perhaps the analogy is most productive here. Machine alignment is different because you can’t bolt accountability onto a system built from units that lack capacity to hold themselves accountable. RLHF and constitutional AI apply pressure to a passive substrate. Organizational intelligence safety is partly produced because we build with units that already possess the capacity for normative self-regulation. The accountability structure then amplifies and coordinates something already present.
